
Data science is the process of taking raw information and putting it through the whole data lifecycle process in order to extract valuable insights that will help business take more informed decisions.
Tectonas is one of the leading experts when it comes developing methods for recording storing and analyzing data effectively from both structures and unstructured formats to extract key pieces of information.
Our Data scientists are curiously data driven individuals with high level technical skills who are capable of studying complex algorithms and synthesize large amounts of information to answer questions and drive strategy.
This is essentially done in two ways :
1. Natural Language processing (NLP)
2. Analyzing Large Data pattern Services
Natural Language processing or as it is popularly known NLP is a brand of artificial intelligence that helps computers understand, interpret and manipulate human language.
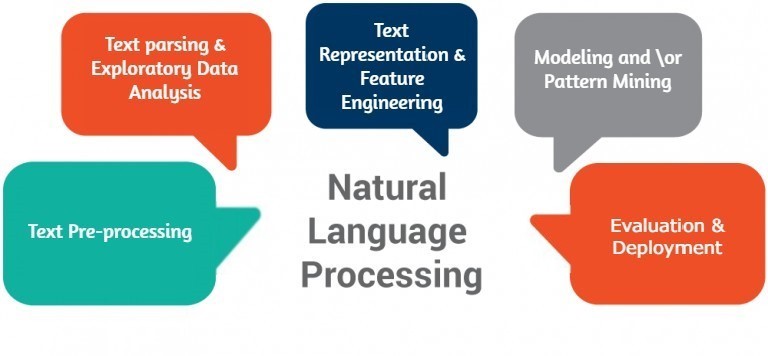
At Tectonas, we follow NLP that helps us to leverage tools, techniques and algorithms to process and understand NLP based data which is usually unstructured text or speech.
This is achieved via Natural Language understanding (NLU) and Natural Language Generation (NLG). NLU takes data input and maps it into natural language while NLG helps in extracting and retrieving information, sentiment analysis etc.
NLP helps in ordering documents or text files based on the chronology of events or occurrences which are mentioned in the files.
NLP will also help us in extracting a document summary which lets you understand what the contents of the original document have.
Large Data sets require a more refined approach to analyze them. At Tectonas we have two approaches to it.
Tectonas uses data pre-processing as a data mining technique that helps in transforming large amounts of information's into an understandable format.
There are various stages that a data pre-processing has to go through before it can make sense:
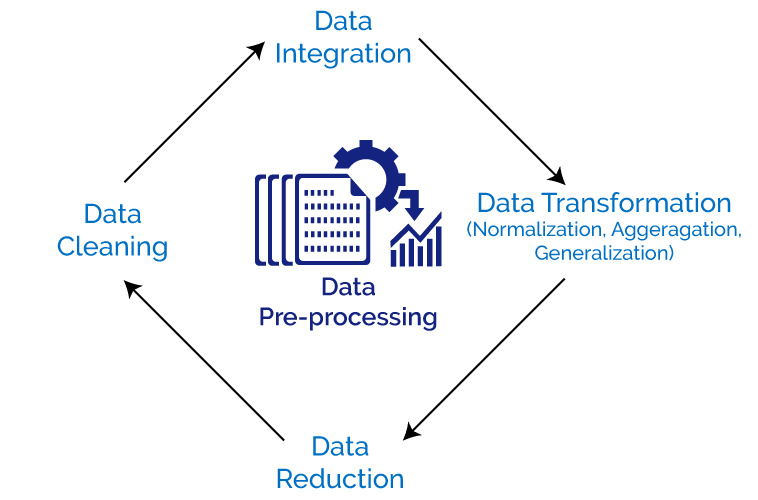
1. Data Cleaning:
As the name suggests, this stage involves data cleansing which means filling in missing values, smoothen out noisy data, identify or remove outliers and resolve inconsistencies.
2. Data Integration :
This stage involves combining data from multiple sources into a coherent data warehouse.
3. Data Transformation:
Data transformation stage helps in rectifying any inconsistency.
4. Data Reduction:
The final stage involves extracting complete data but more qualified ones. Hence the volume of data may be lesser but will give the same analytical results.
The Second approach that Tectonas follows is pattern reduction. Here the data that has been extracted is then analyzed for patterns via machine learning algorithms. There are various steps involved in this process too.
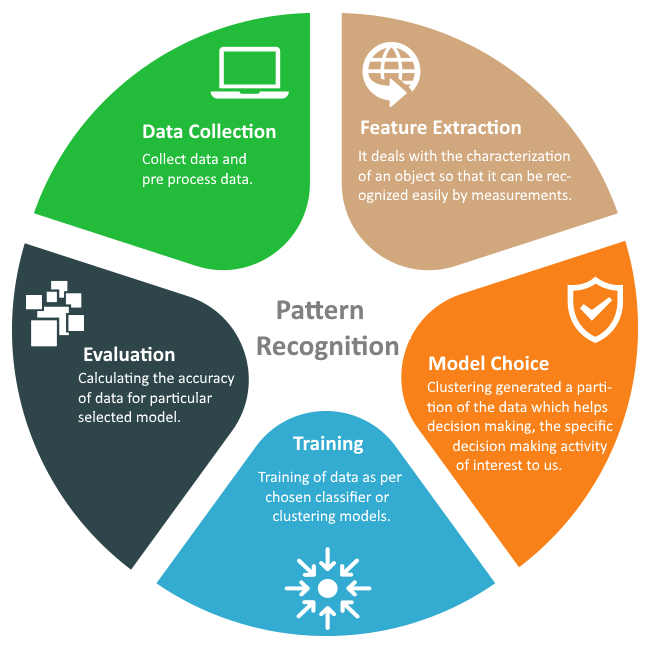
Data Collection and Pre-Processing: Collect data and pre-process data.
Feature Extraction: Here the data is differentiated on the basis on their values. If they have similar values they are grouped together whereas if they are different then they are put into different categories.
Model Choice or Clustering: Here the data that show similar sets of patterns are classified with a label and made into clusters.
Training: Training of data as per chosen classifier or clustering models.
Evaluation: Finally the data sets is analyzed for accuracy as pre the particular model that has been selected.